
یکی از ویژگیهای معرفیشده برای اندروید ۱۰، قابلیت زیرنویس خودکار بدون نیاز به اتصال اینترنت است؛ اما این قابلیت چگونه عمل میکند؟
وجود زیرنویس در محتوای صوتی برای ناشنوایان و کم شنوایان ضروری است، اما برای عموم مردم نیز وجود آن عاری از بهره نیست. تماشای ویدیوهای بیصدا در قطار، جلسات، هنگامی که کودکان خوابیدهاند و مواردی از این قبیل معمولا امر رایجی است و همچنین مطالعات نشان میدهند که وجود زیرنویس، مدت زمانی را که کاربر صرف تماشای فیلم میکند، حدود ۴۰ درصد افزایش میدهد. در حال حاضر قابلیت پشتیبانی از زیرنویس بهصورت یکپارچه در میانِ برنامهها و حتی در درون آنها وجود ندارد. به همین دلیل در حجم قابل توجهی از محتوای صوتی از جمله وبلاگهای پخش ویدیوهای زنده، پادکستها، ویدیوهای محلی، پیامهای صوتی و رسانههای اجتماعی، امکان دسترسی به زیرنویس وجود ندارد.
Live Caption، یکی از نوینترین و جالبترین ویژگیهای سیستمعامل اندروید است که به کمک شاخهای وسیع و پر کاربرد از هوش مصنوعی با نام یادگیریِ ماشین، جهت تولید زیرنویس برای انواع ویدیوهای تحت وب و محلی در گوشیهای هوشمند مورد استفاده قرار میگیرد. تولید زیرنویس، بهصورت آنی و با استفاده از اطلاعات محلیِ خود گوشی، بدون نیاز به منابع آنلاین صورت میگیرد که نتیجهی آن حفظ بیشتر حریم خصوصی و کاهش زمان ایجاد زیرنویس خواهد بود. گوگل در وبلاگ رسمیِ این شرکت پستی را منتشر کرده که جزئیات دقیقی از نحوهی عملکرد این ویژگیِ عالی را نشان میدهد. عملکرد یاد شده با استفاده از مدلهای ژرف یادگیری ماشین در سه مقطع مختلف در این فرایند ایجاد میشود.
مقالههای مرتبط:
در وهلهی نخست مدلی بهصورت RNN-T، یا همان هدایت دنبالهی شبکه عصبی بازگشتی برای تشخیص گفتار وجود دارد. RNN، بهمعنیِ شبکهی عصبی بازگشتی یا مکرر، کلاسی از شبکههای عصبی مصنوعی است که در آن اتصالات بین، گرههایی از یک گراف جهتدار در امتداد یک دنبالهی زمانی هستند و این امر سبب میشود تا الگوریتم بتواند موقتا رفتار پویایی را به نمایش بگذارد. برخلاف شبکههای عصبی رو به جلو، شبکههای عصبی مکرر میتوانند از وضعیت درونی خود برای پردازش دنبالهی ورودیها استفاده کنند که این ویژگی آنها را برای مواردی نظیر تشخیص صوت، یا تشخیص دستنوشتههای غیربخشبندی شدهی متصل مناسب میکند.
برای انجام پیشبینیهای نگارشی نیز گوگل از شبکهی عصبی مکرر مبتنی بر متن استفاده میکند. سومین استفاده از مدلهای یادگیری ماشین شامل یک CNN، یا همان شبکهی عصبیِ پیچشی برای تحلیل رویدادهای صوتی نظیر آواز پرندگان، کف زدن افراد و موسیقی است. شبکههای عصبی پیچشی یا همگشتی ردهای از شبکههای عصبی مصنوعی ژرف هستند که معمولاً برای انجام تحلیلهای تصویری یا گفتاری در یادگیری ماشین استفاده میشوند. گوگل چنین عنوان کرد که این مدل از یادگیریِ ماشین، برگرفته شده از تلاش آنها در جهت ارتقاء نرمافزار accessibility Live Transcribe است. نرمافزار یادشده در سیستمعامل اندروید به کاربران اجازهی تبدیل گفتار به متن را میدهد. در نهایت Live Caption، در جهت ایجاد یک زیرنویس واحد، سیگنال دریافتی از سه مدل یادگیریِ ماشین شامل: RNN-T ،RNN و CNN را با یکدیگر ادغام میکند و زیرنویس بهصورت بیوقفه و درنتیجهی جریان صدا نمایش داده میشود.
گوگل میگوید اقدامات بسیاری برای کاهش توان مصرفی و همچنین بر طرف کردن نیازهای عملکردیِ Live Caption انجام شده است. برای اولینبار، موتور تشخیص خودکار صدا «ASR»، فقط در هنگام شناساییِ گفتار اجرا میشود و در پسزمینه غیرفعال خواهد بود. گوگل در وبلاگ خود مسئله را اینگونه تشریح میکند:
بهعنوان مثال زمانیکه صوت دریافتی بهعنوان موسیقی تشخیص دادهشود و جریان صدا عاری از گفتار باشد، برچسب MUSIC در صفحهنمایش داده شده و موتور تشخیص خودکار صدا بارگذاری نمیشود. ASR تنها زمانی در حافظه بارگذاری میشود که گفتار مجددا در جریان صدا به وجود آید.
گوگل همچنین از تکنیکهای هوش مصنوعی مانند هرس اتصال عصبی (neural connection pruning) که به وسیلهی کاهش اندازهی مدل گفتار انجام میگیرد نیز استفاده کرده و فرایند را بهصورت کلی بهینهسازی کرده است. به همین دلیل توان مصرفی در حدود ۵۰ درصد کاهش مییابد که همین امر سبب اجرای مداوم Live Caption میشود. با وجود تمامیِ بهینهسازیها در مصرف انرژی، این ویژگی در بیشتر حالات از جمله تشخیص جریانهای کوتاه صدا و مکالمات تلفنی با پهنای باند کمِ دامنهی صوتی و نیز در هنگام وجود سروصدا در پسزمینهی محتوای صوتی، از عملکرد خوبی برخوردار است.
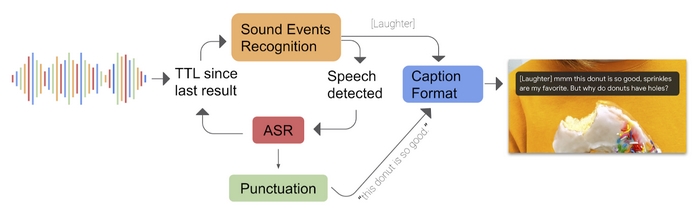
گوگل تشریح میکند که مدل نگارشیِ مبتنی بر متن، در جهت اجرای مداوم و بهصورت محلی روی گوشیِ هوشمند، به یک معماریِ معادل کوچکتر از فضای ابری مجهز شده و سپس به کمک قابلیت TensorFlow Lite، برای کار روی سختافزار بهینه شدهاست. به دلیل شکل گیریِ زیرنویس، نتایج تشخیص گفتار چندین بار در هر ثانیه بهروزرسانی میشوند و به منظور کاهش نیاز به منابع، پیشبینیهای نگارشی بر دنبالهی متن، از تجزیه و تحلیل آخرین جملهی شناسایی شده از گفتار صورت میگیرد.
هماکنون Live Caption، در گوشیهای هوشمند گوگل پیکسل 4 در دسترس قرار دارد و گوگل اعلام کرده است که این ویژگی بهزودی برای پیکسلهای سری 3 و سایر دستگاهها نیز منتشر خواهد شد. این شرکت در تلاش است تا Live Caption را در سایر زبانها نیز کاربردی کند و ویژگی مذکور را برای پشتیبانی از محتوای دارای قابلیت multi-speaker، یا همان پخشکنندهی چندگانهی صدا ارتقا دهد.
.: Weblog Themes By Pichak :.
